Data Cleaning
In order to make our predictor robust to all kinds of game, here are some outliers we trimmed form our training data sets.
- Preorder price instance ( this cause some field been negative )
- Free games
- Game’s original price duration > 250 days (which means it never have discount)
Balance Binary features and Time relative features
Recall that we vectorise metadata feature, such as “Publisher” and “Genres” into binary features. These features are consistent across time, therefore they won’t contribute much information to help our prediction . In order words, time relative feature is relatively less than the binary features. This cause our predictor can not reach satisfy performance no matter how much we increase data sets. We need to find a way to add more time relative feature.
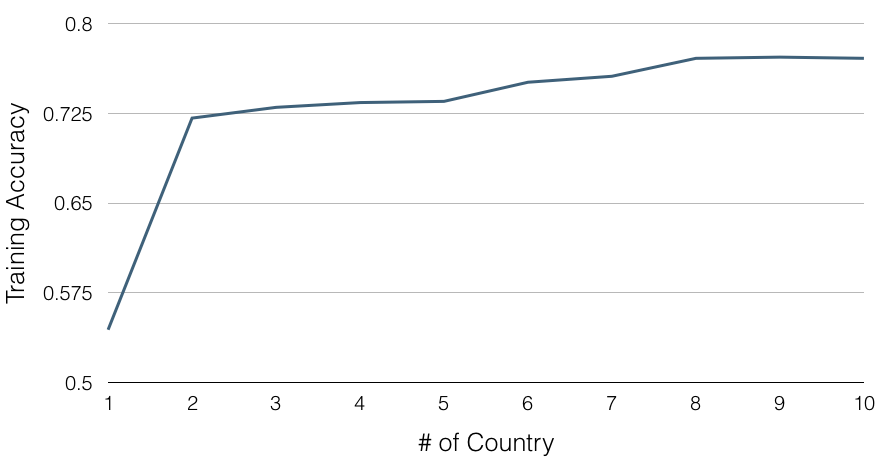
Luckily, Steams is an online global market, same game will have different price across the different country, even though some of the countries have same discount timing, but still have a slight difference. We believe that publishers have same promotion mechanism in the different country, therefore the more different country price we collect, the more likely our predictor can capture the promotion mechanism. And we do more than believe it. We put it into a test. As the chart above, as we increase more countries of time relative feature the training accuracy is also increased and at the end reach up to 75%. This is a strong proof to our optimisation.
Add Absolute Time feature
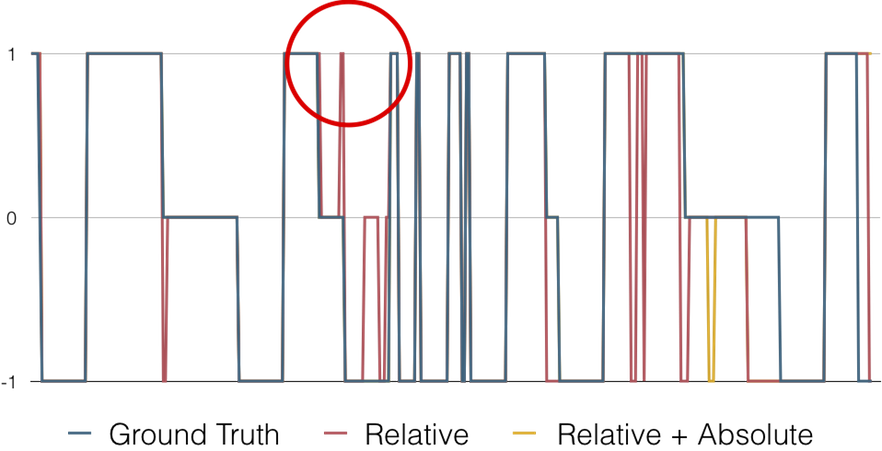 At first, we only use relative time features such as days passed since the last discount. As the chart above, we found some sharp spit spike appeared in our first prediction ( Red line ). We later found we didn’t add the month, weekdays these kinds of absolute time features, which will cause our predictor have abnormal predictions. Adding absolute time features will also let predictor capture some important Steam promotion mechanism such as “weekend deal”.
At first, we only use relative time features such as days passed since the last discount. As the chart above, we found some sharp spit spike appeared in our first prediction ( Red line ). We later found we didn’t add the month, weekdays these kinds of absolute time features, which will cause our predictor have abnormal predictions. Adding absolute time features will also let predictor capture some important Steam promotion mechanism such as “weekend deal”.